
专题:DeepSeek为何能飘荡公共AI圈
中国AI初创公司深度求索(DeepSeek)推理大模子R1的发布在AI社区激励了冲击波,颠覆了东说念主们对已毕顶端AI性能所需条款的假定。与OpenAI的o1比拟,其成本仅为3%-5%。这种开源模式不仅诱骗了斥地东说念主员,还挑战了企业从头想考其AI政策。
这对企业AI政策的影响是真切的。跟着成本的镌汰和绽放获取,企业咫尺有了像OpenAI这么清翠的独到模子的替代品。DeepSeek的发布不错使顶端AI功能的获取民主化,使微型组织粗略在AI武备竞赛中灵验竞争。
在一组第三方基准测试中,涵盖从复杂问题措置,到数学和编码的准确性方面,DeepSeek模子的发达优于Meta Llama 3.1、OpenAI的GPT-4o和Anthropic的Claude Sonnet 3.5。
微软CEO萨蒂亚·纳德拉(Satya Nadella)周三在瑞士达沃斯举行的天下经济论坛上示意:“看到DeepSeek的新模子,不管是他们奈何信得过灵验地完成了一个开源模子来进行推理时辰计较,照旧计较效劳方面,都令东说念主印象深刻。咱们应该颠倒崇拜地对待这一发展。”
咫尺,该模子已飙升至HuggingFace高下载量最高的热点模子。同期,在苹果商店好意思区免费榜名依次四,超过Google Gemini和Microsoft Copilot等好意思国生成式AI产物。

转向纯强化学习
DeepSeek-R1偏离了庸俗用于磨练大型谈话模子(LLM)的传统监督微调(SFT)经过。SFT是AI斥地的圭臬门径,触及在全心计划的数据集上磨练模子,训诫它们缓缓推理,闲居被称为想维链(CoT)。这被以为对提高推理才气至关紧迫。但DeepSeek通过完全跳过SFT来挑战这一假定,转而聘用依赖强化学习(RL)来磨练模子。
这一骁勇举措迫使DeepSeek-R1斥地零丁的推理才气,幸免了法度性数据集闲居引入的脆弱性。天然出现了一些颓势,并导致团队在构建模子的临了阶段从头引入了有限数目的SFT,但适度阐明了根人道的打破:仅强化学习就不错带来显赫的性能进步。
微软AI前沿盘考实验室的首席盘考员Dimitris Papailiopoulos称,R1最让东说念主诧异的是它的工程浮浅性。他说:“DeepSeek旨在取得准确的谜底,而不是珍摄说明每个逻辑门径,从而在保合手高水平效劳的同期显赫减少计较时辰。”
埃默里大学(Emory University)信息系统助理老师Hancheng Cao示意:“这可能是一个信得过的平衡打破,对资源有限的盘考东说念主员和斥地东说念主员来说是件善事,尤其是来自南半球的盘考东说念主员。”
成绩于开源
DeepSeek在很猛进程上使用了开源。DeepSeek最初为其独到聊天机器东说念主斥地AI模子,然后将其发布供公众使用。东说念主们对该公司果真凿设施知之甚少,但它很快将其模子开源。
为了磨练其模子,DeepSeek购买了10000多块英伟达GPU,随后又扩大到50000块。与OpenAI、谷歌和Anthropic等泉源的AI实验室比拟,这显着小巫见大巫,因为这些实验室每个都有逾越50万块GPU。
外交平台X的用户Silver Spook称:“感谢中国公司Deepseek,他们斥地的DeepSeek-R1贯通,生成式AI是一个被老本族夸大的纷乱骗局,其实质价值不到550万好意思元。”(注:英伟达工程师Jim Fan称,DeepSeek在两个月内以558万好意思元的预算磨练了其基础模子V3。)
DeepSeek以有限的资源已毕存竞争力的适度的才气,凸显了始创性和明慧睿智。此外,DeepSeek从一启动就颠倒具有更始性。引入了大众羼杂系统(MoE)和多头潜在提防力(MhLA)。
DeepSeek-R1之是以带来如斯多的惊喜,是因为开源模子背后有着纷乱的逻辑和能源。它们的免费成本和延展性是此类模子将在企业中顺利的原因。
关于企业有筹备者来说,DeepSeek的得手凸显了AI领域更庸俗的飘荡:更精简、更高效的斥地执行越来越可行。一些组织可能需要从头评估与独到AI提供商的贯串关连。
Meta首席AI科学家Yann LeCun称,DeepSeek的得手凸显了保合手AI模子开源的价值,这么任何东说念主都不错从中受益。这标明开源模式正在超过独到模式。LeCun说:“他们提议了新的主义,并将其确立在其他东说念主的责任之上。因为他们的责任是公开和开源的,每个东说念主都不错从中赢利。这便是绽放盘考和开源的力量。”
外交平台X的用户Niels Rogge称:“有一家名为DeepSeek的中国公司,它基本上作念了OpenAI最初盘动作念的事情。他们开源了一个经过大界限强化学习磨练的模子,打败了其他悉数东说念主,致使还发表了一篇珍摄先容其经过的论文。”

糜掷者受益
天然DeepSeek的更始是打破性的,但它毫不是确立了皆备的阛阓泉源地位。因为它发表了盘考适度,其他模子公司将从中学习并顺应。Meta和法国开源示范公司Mistral可能会落伍,但他们可能只需要几个月的时辰就能赶上。
最终,糜掷者、初创公司和其他用户将赢得最大的得手,因为DeepSeek的产物将链接将使用这些模子的价钱推到接近零的水平。这种快速的商品化可能会给在独到基础设施上参加巨资的泉源AI提供商带来挑战,致使是纷乱的灾难。
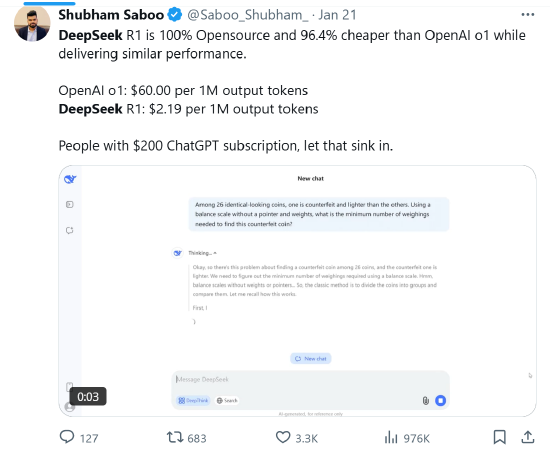
外交平台X的用户Shubham Saboo称:“DeepSeek R1 100%开源,比OpenAI o1低廉96.4%,同期提供同样的性能。OpenAI o1每1M输出Token为60好意思元,而DeepSeek R1每1M输出Token为2.19 好意思元。领有200好意思元ChatGPT订阅的东说念主,请仔细议论一下。”
正如好多评述家所说,包括Meta的投资者兼前高管Chamath Palihapitiya,这可能意味着OpenAI和其他公司多年的运营开销和老本开销将被浪费。
OpenAI投资答复问题
这一切都激励了东说念主们对OpenAI、微软和其他公司所追求的投资贪图的要紧质疑。
OpenAI耗资5000亿好意思元的Stargate形势反应了其缔造大型数据中心以支柱其先进模子的甘心。在甲骨文和软银等贯串伙伴的支柱下,这一政策的前提是,已毕通用东说念主工智能(AGI)需要前所未有的计较资源。
然则,DeepSeek以极低的成本展示了一种高性能模子,这对这种设施的可合手续性提议了挑战,激励了东说念主们对OpenAI为如斯纷乱的投资带往来报的才气的怀疑。
企业家兼评述员Arnaud Bertrand捕捉到了这种动态,将DeepSeek省俭、漫步的更始,与OpenAI等其他斥地商对结合、资源密集型基础设施的依赖,进行了对比。
Bertrand称,天下坚韧到以DeepSeek为代表的斥地商在技艺和更始方面还是赶上了OpenAI等传统斥地商,在某些领域致使逾越了他们。
位于多伦多的技艺参谋人Reuven Cohen自12月下旬以来一直在使用DeepSeek-V3。他说,它不错与OpenAI、谷歌和旧金山初创公司Anthropic的最新系统相比好意思,何况使用起来要低廉得多。
Cohen说:“DeepSeek是我省钱的一种阵势。这是像我这么的东说念主想要使用的技艺。”

海量资讯、精确解读,尽在新浪财经APP
株连剪辑:刘亮堂 欧洲杯体育


